South African languages present a variety of linguistic features. Let us have a quick (computational) look at the inside of words: morphology.
A small multiparallel corpus [1] of around 2000 sentences in all S.A. languages will allow us to get some quantitative insight into the difficulties raised by each language. Every English sentence has been translated into the other 10 languages. It allows us to compare the number of words or rather tokens, since we also count punctuation and the number of types – that is the number of different tokens. A language with a reach morphology (with for instance, markers on verbs for conjugation or cases on nouns etc) should display more token types. An agglutinative language in particular (where long words are formed, by composition of lexical items and addition of grammatical morphemes) will also display a lesser number of tokens.
| Language | #tokens | #types |
| English | 50k | 8k |
| Afrikaans | 55k | 6k |
| Zulu | 41k | 13k |
| Northern Sotho | 63k | 5k |
No need I guess to extend on English. Afrikaans, a language rooted from Dutch is the other language of the Germanic family in the set of 11 official languages. Compared with Dutch, it displays a more regular morphology [2]. Part-of-speech (POS) tagging (tagging each word with a label such as: noun, verb, adjective, preposition…) for Afrikaans works relatively well.
As far as Bantu languages are concerned, I will stick for now to Nguni (represented here by Zulu) and Sotho languages (represented here by Northern Sotho).
Even if due to their written form (conjunctive for the Nguni languages, disjunctive for the Sotho languages), each of those two results in distinctive challenges as far as computational processing is concerned.
Part-of-speech tagging
First, automatic tagging tasks, such as POS tagging are mostly performed using machine learning techniques. They learn statistical models from data- annotated (a number of sentences have been manually labelled) or not (raw text). This learning task is rendered more difficult by an extended vocabulary (a greater number of different tokens), since more of them will be seen once or too few times in the data. And new data (unseen text) will be more likely to contain unseen words. That is a general problem called “data sparsity”.
Thus, among the four languages presented here, Zulu offers the greatest challenge: rare, long words – a similar situation to Finnish. The table above shows how the Zulu version does present fewer words, with more types.
Creating a rule-based analyser (manually write rules to annotate the data) might still be problematic. First of all, such approach requires a lexicon to be able to parse the data. Second of all, there will always remain a level of ambiguity with which a rule-based approach might struggle with, for lack of a quantified, data-supported method to solve it.
Northern Sotho is expected to be easier for that reason: every morpheme is written as a separate word, instead of being glued to the lexical unit it applies to, as in Zulu. The consequence is a greater number of tokens, with fewer types: data sparsity will not hurt as much.
Word alignment
Second, such linguistic features will have consequences for the task of aligning words across languages (in bilingual corpora). Such a task is performed automatically using statistical models, such as the famous IBM models (). These models rely on the assumption of small local variations around a one-one alignment with words coming in the same order between the two languages.
Let us envisage the case of English-to-XX alignment.
Long distance movement between languages, as in the case of Afrikaans double negation, hinders word alignment:
Die plig om ‘n familielid te onderhou is nie beperk tot die onderhoud van ‘n kind nie .
(the duty to support a family member is not limited to supporting a child .)
But the major issue lies within agglutination, either by composition of new lexical units (Afrikaans), or by combination of multiple grammatical morphemes around the lexical stem (Zulu and to a much lesser extent, Northern Sotho).
The following histogram illustrates the discrepancies between the four languages. It shows the ratio of token types for each range of character length.
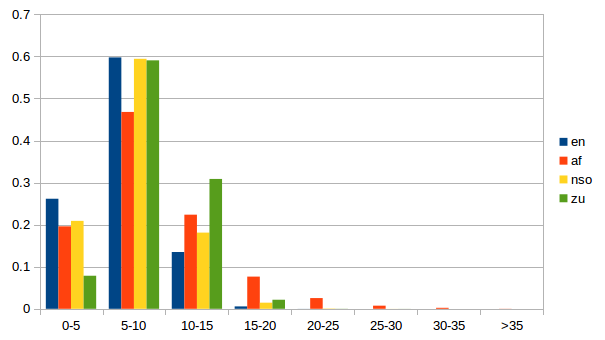
Zulu probably displays the greater discrepancy with English. One possibility to improve alignment with English is to process the corpus with a morphological analyser, such as Morfessor [3], and thus reduce the gap between ENG and the other language.
Northern Sotho, because of its disjunctive writing, is expected to be more easily aligned using the algorithms mentioned earlier.
Finally, here are examples of long words (longest words in our small multiparallel corpus):
Afrikaans: ontwikkelingsfinansieringsinstansies
[ontwikkeling s finansiering s instansie s]
(institutions of financial development)
Northern Sotho: seswantšhokakaretšo
(the whole picture)
Zulu: kwayisishiyagalombili
(eight) (sic!)
FURTHER
[1]Eiselen, E. & Puttkammer, M. Developing text resources for ten South African languages Proc. LREC, 2014 Link
[2]Comparison of Afrikaans and Dutch (Wikipedia) Link
[3]Morfessor 2.0: Toolkit for statistical morphological segmentation Link