As I mentioned in an earlier post, South African academies seem to be buzzing about multilingualism. In that prospect, technology surely has its part to play.
Indeed, providing a multilingual access to education may involve publishing learning material in the involved languages. That may be a case for the use of machine translation or computer aided translation.
A lesser version of this would be to provide students with linguistic help tools. For instance, such a tool that would provide a translation of a subject-specific phrase or “term” in the student’s language. Ideally with some definition for it.
A first step into that direction would be, for each subject, to identify its specific lexicon. This can be learnt from corpus, precisely from existing learning material. Such learning material is likely to be available in the dominant language (in our case, English and, to a lesser extent, Afrikaans) from which we may want to translate, for the purpose of knowlege dissemination. We would like to learn which are the terms specific to a subject, and which are more specific than others, by assigning each term a subject-specific score. Once term phrases are extracted, a basic implementation of that idea would make use of term frequency–inverse document frequency (see end of post). By composing the number of times a term is seen in a document (or, alternatively, in a range of documents within a given topic) by the (inverse of the) number of documents (or topics) containing that term, it gives an indication of its relevance to the topic.
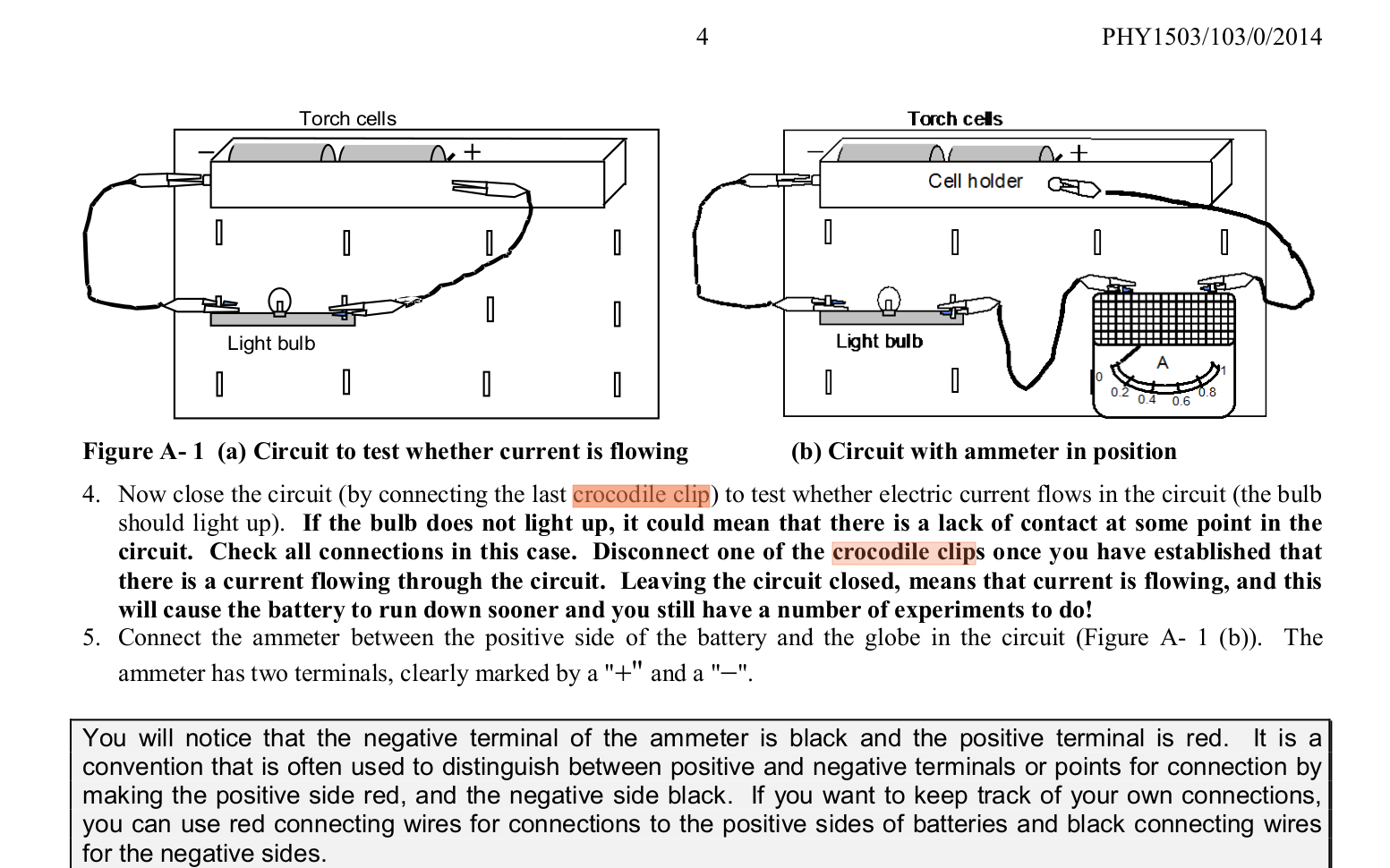
Here is what I got for the subject of physics in one of my experiments, extracting noun phrases from learning material corpus.
| Relevance Rank | Term |
|---|---|
| 1 | Physics |
| 2 | magnetic field |
| 3 | Physics Department |
| 4 | sin |
| 5 | kg |
| 6 | cm |
| 7 | home experiment |
| 8 | equation |
| 9 | electric field |
| 10 | potential difference |
| 11 | radius |
| 12 | magnitude |
| 13 | eq |
| 14 | resistor |
| 15 | science library |
| 16 | angle |
| 17 | fl |
| 18 | wire |
| 19 | ammeter |
| 20 | coil |
| 21 | Physics PO Box |
| 22 | simple pendulum |
| 23 | experiment |
| 24 | Hz |
| 25 | practical session |
We might want to exclude some of those terms (like the trigonometric functions or the measure units). The term “practical session”, might better be ranked lower, since it could also belong to a dfew other subjects, such as biology, geology but why not also arts or engineering.
Now can we perform such an extraction of (monolingual) terms in another language, for instance Northern Sotho?
Let’s have a look at a first attempt on extracting terms in a single document, in the domain of labour law. Please note that this time, terms are ranked on their frequency in the document, not on their relevance to the domain.
| Frequency Rank | Term |
|---|---|
| 1 | šomana |
| 2 | bala ga tlaleletšo |
| 3 | ao |
| 4 | diteng tša kgaolo |
| 5 | mmotšule |
| 6 | boitekolo |
| 7 | dikgokagano tša go hloka |
| 8 | lefaseng la batho |
| 9 | sephorofešene |
| 10 | tlhalošo ya maleba |
| 11 | tšhomišong |
| 12 | kgaolong |
| 13 | tšwetšopele ya dingangišano |
| 14 | onlaene |
| 15 | karolwana |
| 16 | dikabo ka diselaete |
| 17 | dikabo tša go fiwa |
| 18 | melaetša ya go ngwalwa |
| 19 | mareo a motheo |
| 20 | lefelong la mošomo |
| 21 | tšhate ya para |
| 22 | dikholego |
| 23 | dikgokagano tša go leka |
| 24 | dithuši tša pono ya mahlo |
| 25 | hlogo |
Both those examples were obtained usinig a terminology extraction pipeline we are busy building. Such technology involves the use of technological components that are more or less standard and readily available (actually plentiful, for English) or rarer, still to be crafted and generally speaking less efficient for less-resourced languages. That involves tools to automatically identify the language of a text, splitting the text into sentences, words…tagging those words with a part of speech (is it a Noun , a Verb? an Adjective ?… ), using some grammar to extract phrases and not only single words. Then comes the statistical machinery that turns word counts into meaningful scores (such as the relevance score previously mentioned).
To go further, one could turn to translated material as a source for term extraction, extracting or sorting this time, bilingual or multilingual terms. Such a resource would be precious for the purpose of translation (however being extracted from… existing translations!) or the crafting of software tools for linguistic support.
FURTHER